Cython 基本用法
我一直非常喜欢 Python。当人们提到 Python 的时候,经常会说到下面两个优点:
- 写起来方便
- 容易调用 C/C++ 的库
然而实际上,第一点是以巨慢的执行速度为代价的,而第二点也需要库本身按照 Python 的规范使用 Python API、导出相应的符号。
在天壤实习的时候,跟 Cython 打了不少交道,觉得这个工具虽然 Bug 多多,写的时候也有些用户体验不好的地方,但已经能极大提高速度和方便调用 C/C++,还是非常不错的。这里就给大家简单介绍一下 Cython(注意区别于 CPython)。Cython 可以让我们方便地:
- 用 Python 的语法混合编写 Python 和 C/C++ 代码,提升 Python 速度
- 调用 C/C++ 代码
例子:矩阵乘法
假设我们现在正在编写一个很简单的矩阵乘法代码,其中矩阵是保存在 numpy.ndarray 中。Python 代码可以这么写:
# dot_python.py
import numpy as np
def naive_dot(a, b):
if a.shape[1] != b.shape[0]:
raise ValueError('shape not matched')
n, p, m = a.shape[0], a.shape[1], b.shape[1]
c = np.zeros((n, m), dtype=np.float32)
for i in xrange(n):
for j in xrange(m):
s = 0
for k in xrange(p):
s += a[i, k] * b[k, j]
c[i, j] = s
return c
不用猜也知道这比起 C/C++ 写的要慢的不少。我们感兴趣的是,怎么用 Cython 加速这个程序。我们先上 Cython 程序代码:
# dot_cython.pyx
import numpy as np
cimport numpy as np
cimport cython
@cython.boundscheck(False)
@cython.wraparound(False)
cdef np.ndarray[np.float32_t, ndim=2] _naive_dot(np.ndarray[np.float32_t, ndim=2] a, np.ndarray[np.float32_t, ndim=2] b):
cdef np.ndarray[np.float32_t, ndim=2] c
cdef int n, p, m
cdef np.float32_t s
if a.shape[1] != b.shape[0]:
raise ValueError('shape not matched')
n, p, m = a.shape[0], a.shape[1], b.shape[1]
c = np.zeros((n, m), dtype=np.float32)
for i in xrange(n):
for j in xrange(m):
s = 0
for k in xrange(p):
s += a[i, k] * b[k, j]
c[i, j] = s
return c
def naive_dot(a, b):
return _naive_dot(a, b)
可以看到这个程序和 Python 写的几乎差不多。我们来看看不一样部分:
- Cython 程序的扩展名是
.pyx cimport是 Cython 中用来引入.pxd文件的命令。有关.pxd文件,可以简单理解成 C/C++ 中用来写声明的头文件,更具体的我会在后面写到。这里引入的两个是 Cython 预置的。@cython.boundscheck(False)和@cython.wraparound(False)两个修饰符用来关闭 Cython 的边界检查-
Cython 的函数使用
cdef定义,并且他可以给所有参数以及返回值指定类型。比方说,我们可以这么编写整数min函数:cdef int my_min(int x, int y): return x if x <= y else y这里
np.ndarray[np.float32_t, ndim=2]就是一个类型名就像int一样,只是它比较长而且信息量比较大而已。它的意思是,这是个类型为np.float32_t的2维np.ndarray。 - 在函数体内部,我们一样可以使用
cdef typename varname这样的语法来声明变量 - 在 Python 程序中,是看不到
cdef的函数的,所以我们这里def naive_dot(a, b)来调用cdef过的_naive_dot函数。
另外,Cython 程序需要先编译之后才能被 Python 调用,流程是:
- Cython 编译器把 Cython 代码编译成调用了 Python 源码的 C/C++ 代码
- 把生成的代码编译成动态链接库
- Python 解释器载入动态链接库
要完成前两步,我们要写如下代码:
# setup.py
from distutils.core import setup, Extension
from Cython.Build import cythonize
import numpy
setup(ext_modules = cythonize(Extension(
'dot_cython',
sources=['dot_cython.pyx'],
language='c',
include_dirs=[numpy.get_include()],
library_dirs=[],
libraries=[],
extra_compile_args=[],
extra_link_args=[]
)))
这段代码对于我们这个简单的例子来说有些太复杂了,不过实际上,再复杂也就这么复杂了,为了省得后面再贴一遍,所以索性就在这里把最复杂的列出来好了。这里顺带解释一下好了:
'dot_cython'是我们要生成的动态链接库的名字sources里面可以包含.pyx文件,以及后面如果我们要调用 C/C++ 程序的话,还可以往里面加.c/.cpp文件language其实默认就是c,如果要用 C++,就改成c++就好了include_dirs这个就是传给gcc的-I参数library_dirs这个就是传给gcc的-L参数libraries这个就是传给gcc的-l参数extra_compile_args就是传给gcc的额外的编译参数,比方说你可以传一个-std=c++11extra_link_args就是传给gcc的额外的链接参数(也就是生成动态链接库的时候用的)- 如果你从来没见过上面几个
gcc参数,说明你暂时还没这些需求,等你遇到了你就懂了
然后我们只需要执行下面命令就可以把 Cython 程序编译成动态链接库了。
python setup.py build_ext --inplace
成功运行完上面这句话,可以看到在当前目录多出来了 dot_cython.c 和 dot_cython.so。前者是生成的 C 程序,后者是编译好了的动态链接库。
下面让我们来试试看效果:
$ ipython 15:07:43
Python 2.7.12 (default, Oct 11 2016, 05:20:59)
Type "copyright", "credits" or "license" for more information.
IPython 4.0.1 -- An enhanced Interactive Python.
? -> Introduction and overview of IPython's features.
%quickref -> Quick reference.
help -> Python's own help system.
object? -> Details about 'object', use 'object??' for extra details.
In [1]: import numpy as np
In [2]: import dot_python
In [3]: import dot_cython
In [4]: a = np.random.randn(100, 200).astype(np.float32)
In [5]: b = np.random.randn(200, 50).astype(np.float32)
In [6]: %timeit -n 100 -r 3 dot_python.naive_dot(a, b)
100 loops, best of 3: 560 ms per loop
In [7]: %timeit -n 100 -r 3 dot_cython.naive_dot(a, b)
100 loops, best of 3: 982 µs per loop
In [8]: %timeit -n 100 -r 3 np.dot(a, b)
100 loops, best of 3: 49.2 µs per loop
所以说,提升了大概 570 倍的效率!而我们的代码基本上就没有改动过!当然啦,你要跟高度优化过的 numpy 实现比,当然还是慢了很多啦。不过掐指一算,这 0.982ms 其实跟直接写 C++ 是差不多的,能实现这个这样的效果已经很令人满意了。不信我们可以试试看手写一次 C++ 版本:
// dot.cpp
#include <ctime>
#include <cstdlib>
#include <chrono>
#include <iostream>
class Matrix {
float *data;
public:
size_t n, m;
Matrix(size_t r, size_t c): data(new float[r*c]), n(r), m(c) {}
~Matrix() { delete[] data; }
float& operator() (size_t x, size_t y) { return data[x*m+y]; }
float operator() (size_t x, size_t y) const { return data[x*m+y]; }
};
float dot(const Matrix &a, const Matrix& b) {
Matrix c(a.n, b.m);
for (size_t i = 0; i < a.n; ++i)
for (size_t j = 0; j < b.m; ++j) {
float s = 0;
for (size_t k = 0; k < a.m; ++k)
s += a(i, k) * b(k, j);
c(i, j) = s;
}
return c(0, 0); // to comfort -O2 optimization
}
void fill_rand(Matrix &a) {
for (size_t i = 0; i < a.n; ++i)
for (size_t j = 0; j < a.m; ++j)
a(i, j) = rand() / static_cast<float>(RAND_MAX) * 2 - 1;
}
int main() {
srand((unsigned)time(NULL));
const int n = 100, p = 200, m = 50, T = 100;
Matrix a(n, p), b(p, m);
fill_rand(a);
fill_rand(b);
auto st = std::chrono::system_clock::now();
float s = 0;
for (int i = 0; i < T; ++i) {
s += dot(a, b);
}
auto ed = std::chrono::system_clock::now();
std::chrono::duration<double> diff = ed-st;
std::cerr << s << std::endl;
std::cout << T << " loops. average " << diff.count() * 1e6 / T << "us" << std::endl;
}
$ g++ -O2 -std=c++11 -o dot dot.cpp
$ ./dot 2>/dev/null
100 loops. average 1112.11us
可以看到相比起随手写的 C++ 程序,Cython 甚至还更快了些,或许是因为 numpy 以及计量方式(取3次最好 vs 取平均)的缘故。
Cython 加速 Python 代码的关键
如果我们把刚刚 Cython 代码中的类型标注都去掉(也就是函数参数和返回值类型以及函数体内部的 cdef),再试试看运行速度:
$ python setup.py build_ext --inplace
$ ipython
In [1]: import numpy as np
In [2]: import dot_python
In [3]: import dot_cython
In [4]: a = np.random.randn(100, 200).astype(np.float32)
In [5]: b = np.random.randn(200, 50).astype(np.float32)
In [6]: %timeit -n 100 -r 3 dot_cython.naive_dot(a, b)
100 loops, best of 3: 416 ms per loop
In [7]: %timeit -n 100 -r 3 dot_python.naive_dot(a, b)
100 loops, best of 3: 537 ms per loop
可以看到,这下 Cython 实现几乎和 Python 实现一样慢了。所以说,在 Cython 中,类型标注对于提升速度是至关重要的。
到了这里就可以吐槽动态类型的不好了。单就性能方面来看,很多编译期间就能确定下来的事情被推到了运行时;很多编译期间能检查出来的问题被推到了运行时;很多编译期间能做的优化也被推到了运行时。再加上 CPython 又没有带 JIT 编译器,这相当于有相当大的时间都浪费在了类型相关的事情上,更不用说一大堆编译器优化都用不了。
分析 Cython 程序
前面说到,Cython 中类型声明非常重要,但是我们不加类型标注它依然是一个合法的 Cython 程序,所以自然而然地,我们会担心漏加类型声明。不过好在 Cython 提供了一个很好的工具,可以方便地检查 Cython 程序中哪里可能可以进一步优化。下面命令既可以对 dot_cython.pyx 进行分析:
cython -a dot_cython.pyx
如果当前 Cython 程序用到了 C++,那么还得加上 --cplus 参数。在成功运行完 cython -a 之后,会产生同名的 .html 文件。我们可以打开看看不带类型标注的版本:
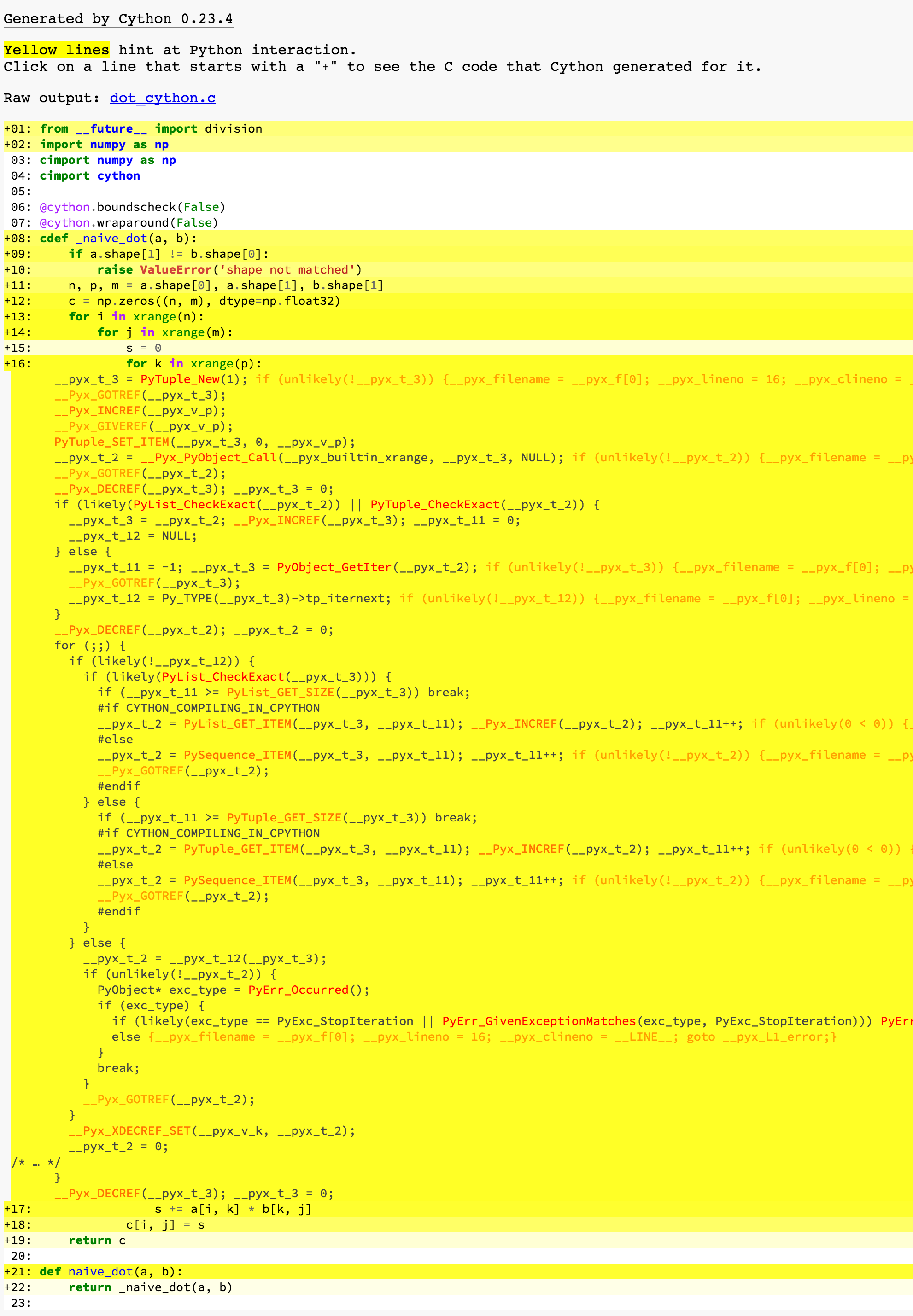
这里用黄色部分标出了和 Python 发生交互的地方,简单地理解,就是拖累性能的地方。点击每一行可以查看相应的生成的 C/C++ 代码。可以看到我们这里几乎每一行都被标了出来(汗……)
这里我们点开了第16行,也就是 for k in xrange(p),可以发现这么一句简单的话,却被展开成了如此复杂的语句,从这一系列 Python API 的名称来看,我们至少额外地做了:创建和销毁 Python Object、增加和减少 Python Object 的引用计数、类型检查、列表长度检查等等……然而在不知道类型的情况下,为保证运行正确,这些事情又是不得不做的。
我们把类型标注加回来,再看看 cython -a 的结果:
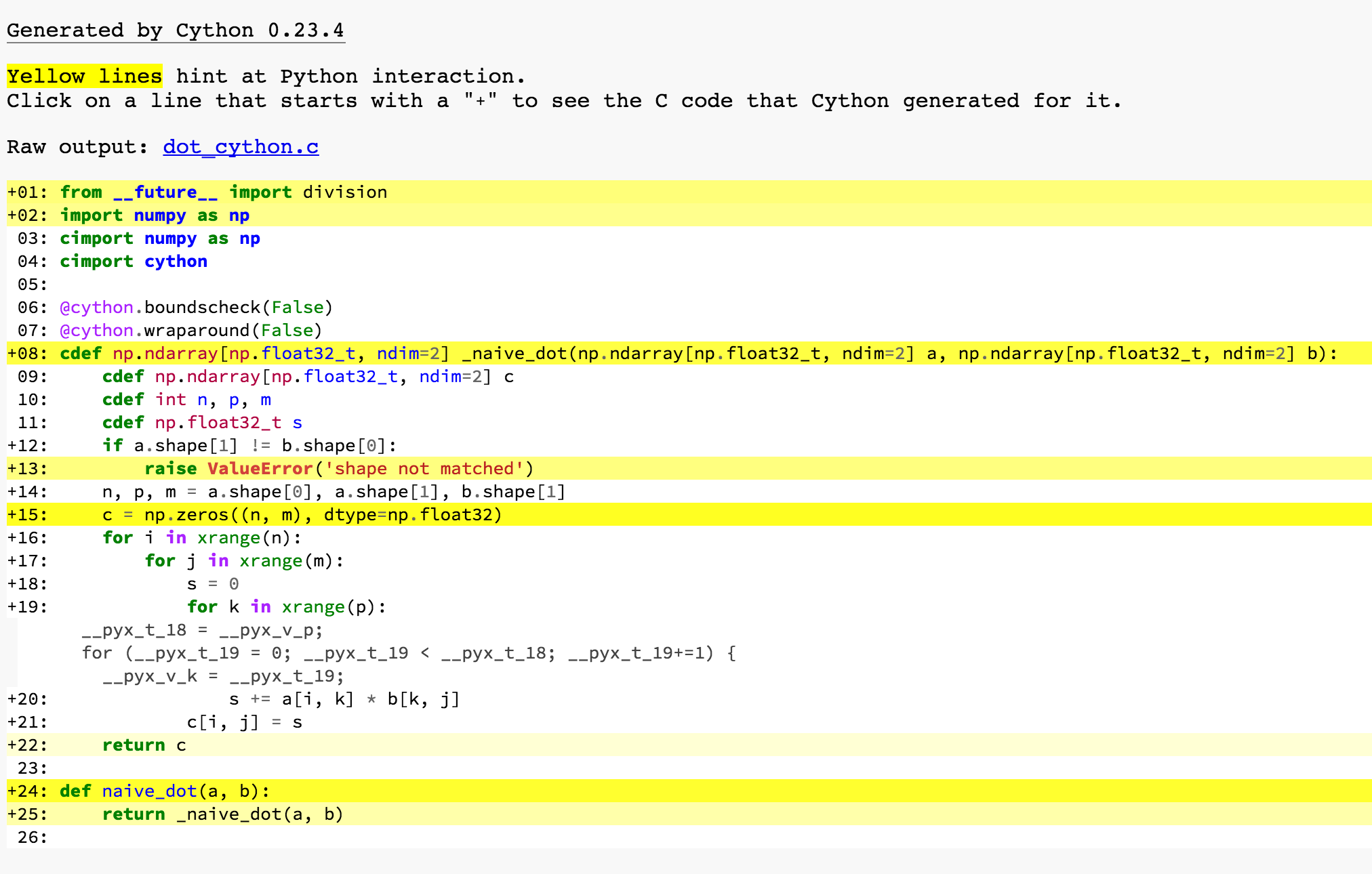
这里同样展开了 for k in xrange(p) 这一行,可以看到,它很直接地就翻译成了 C 里面的 for 循环。其他地方同样也简化了很多,剩下的只有进出函数调用、raise ValueError 和 np.zeros 这些确实是要和 Python 发生交互的地方被标了出来。一般来说,我们把一个 Cython 程序优化到这个地步就行了。
根据 Amdahl’s Law 我们知道(其实根据直觉我们也知道),只要最核心的代码足够快就行了。所以说,我们完全可以放心地编写 Python 代码,享受 Python 带来的好处,同时把核心代码用 C/C++ 或者 Cython 重写,这样就能兼顾开发效率和执行效率了。
以上部分的参考资料:
- Cython for NumPy users
- Faster code via static typing
- Dynamic type languages versus static type languages
- Language Basics
作为胶水
Python 是很好的胶水语言,但是前提是库本身要使用 Python API 来和 Python 交互。有了 Cython 之后,我们可以照常编写 C/C++ 程序,或者是直接拿来一份已有的 C/C++ 源码,然后用 Cython 简单包装一下就可以使用了。
本来我想胶水这一部分也像前面性能提升部分一样详细地写出来。后来想想,其实这一部分主要涉及的就是 Cython 语法本身,没有什么特别值得注意的,所以看看 Cython 文档就好了。我这里把一些特性不完全地列出来:
- 函数签名基本上可以原样从 C/C++ 复制到 Cython 中
- C 中的
_Bool类型和 C++ 中的bool类型在 Cython 中都用bint取代(因为 Python 没有布尔类型)
- C 中的
struct/enum/union是支持的const限定和引用都是支持的- 命名空间是支持的
- C++ 类是支持的
- 部分操作符重载是支持的,部分操作符需要改名
- 内嵌类是支持的
- 模板是支持的
- 异常是支持的
- 构造函数、析构函数是支持的
- 静态成员是支持的
libc/libcpp/ STL 是支持的- 声明写在
.pxd中可以在.pyx中cimport进来 - 你可能需要注意 Python 字符串到各式各样的 C/C++ 字符串的转换
也就是说在 Cython 里面调用 C/C++ 代码应该是没有任何问题的,你想在 Cython 里面用 Python 的语法写 C/C++ 程序基本上也是没有问题的。具体的可以查阅以下资料: