跨机秒传RL模型参数更新的一些后续
上一篇博客介绍了我们如何实现跨机秒传RL模型参数更新。这一篇博客简单补充一些后续:
- Kimi-K2 (1T params),256卡BF16训练,128卡FP8推理,参数更新只需要不到 1.3 秒。
- 参数更新的流水线稍微再优化了一些,增加了两个可以并行的项目:H2D Memcpy 和全局通讯屏障。
- 跑了一遍 PyTorch Profiler,方便直观地分析参数更新流水线,看看时间都花在哪里了。
- 加了一些图方便理解。
流水线优化
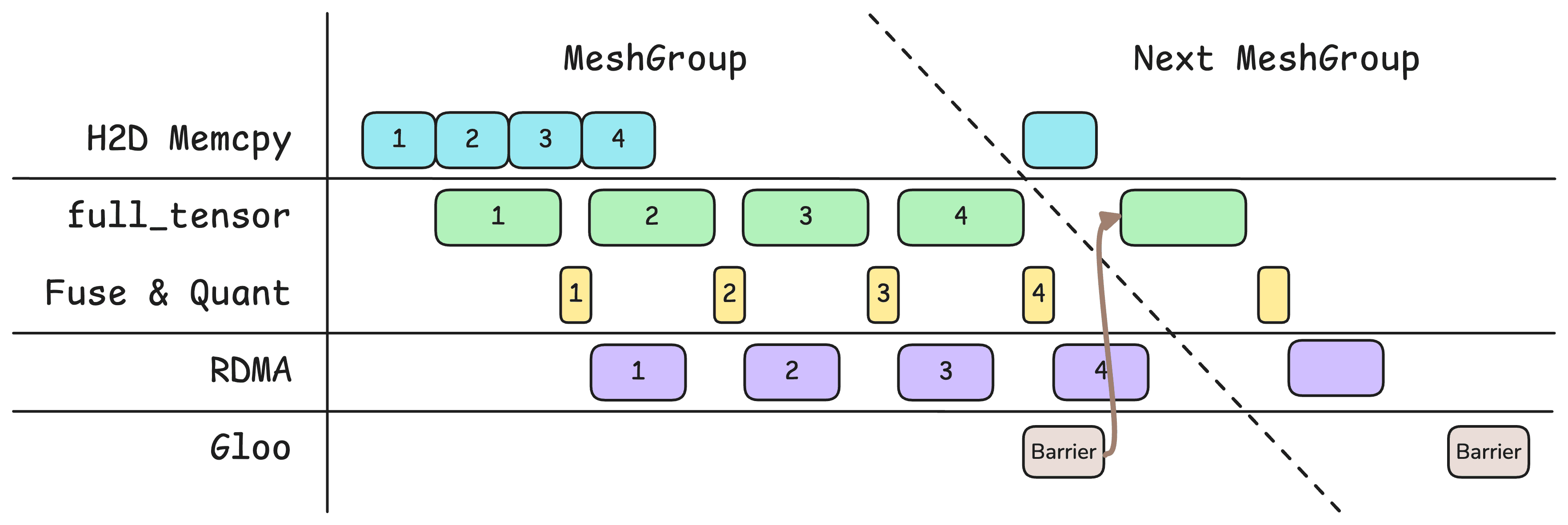
之前的版本只有GPU和网络这两个流水线阶段,现在增加到了四个:
- H2D Memcpy
- GPU 操作:
full_tensor()、投影融合、量化 - RDMA 传输
- 全局通讯屏障:在每个 Mesh Group 的最后一次
full_tensor()之后就可以加一个async_op=True的全局通讯屏障。不用等到 RDMA 传输结束。因为 Gloo 走 Ethernet,所以这又是可以并行的。
PyTorch Profiler
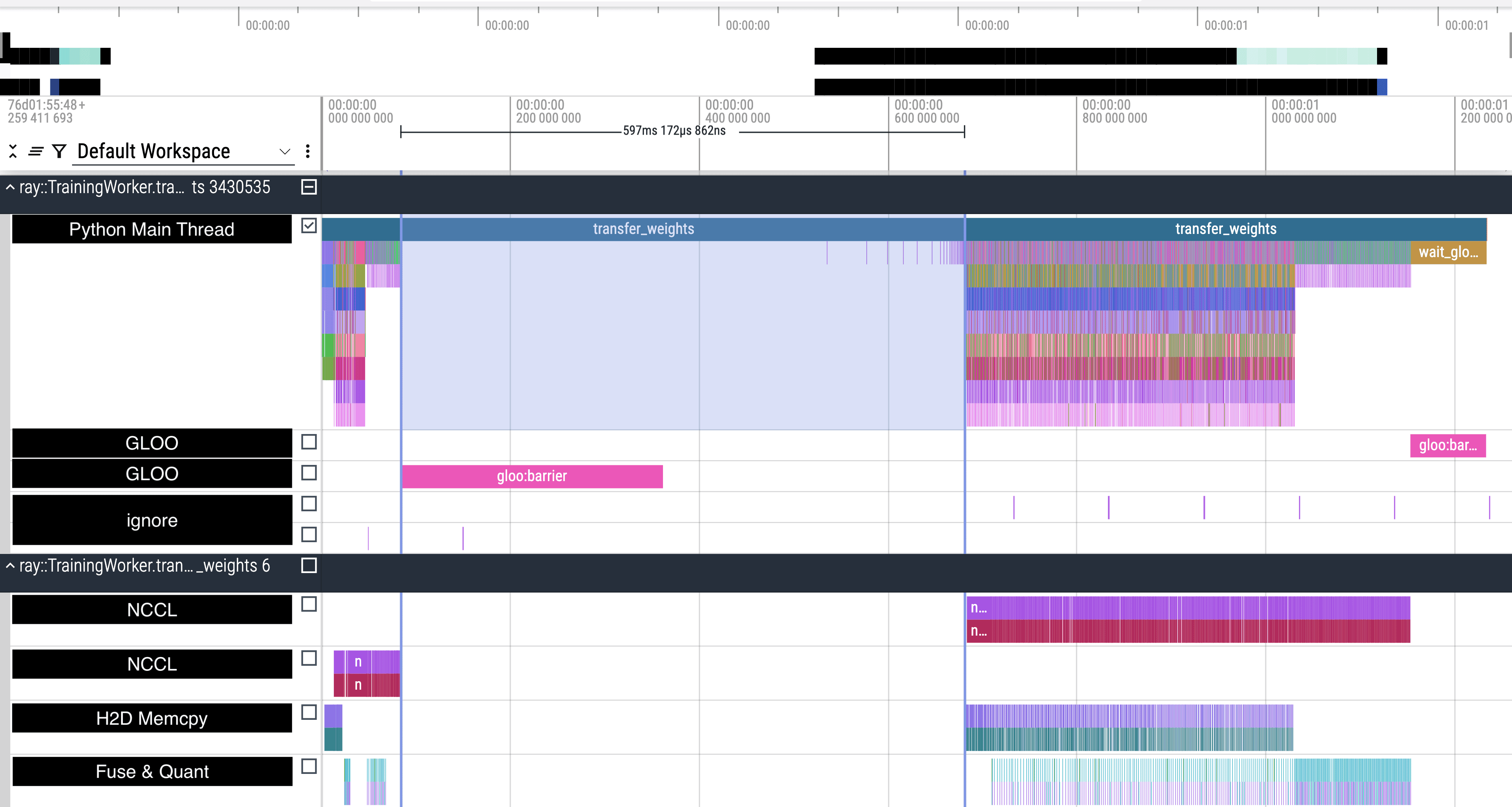
首先看一次完整的参数更新。从上图可以看到,总时间大概1.2秒出头。
参数更新分成了两个 Mesh Group,中间有全局通讯屏障。前面一次是在传非 MoE 参数,FSDP 在机内 NVLink 维度上做切分。后面一次是传 MoE 参数,FSDP 在跨机 RDMA 维度上做切分。
对于非 MoE 参数,full_tensor()(也就是 NCCL all-gather)跑得很快,因为是通过 NVLink 传输的。所以总体上是在等 RDMA 传输。中间的全局通讯屏障也完美地被藏在 RDMA 传输里面了。
对于 MoE 参数,full_tensor() 肉眼可见地拖慢了非常多的速度。全局通讯屏障也没能够被藏起来,也就是 RDMA 传输比全局通讯屏障完成得更早,应该是在等某个跑得特别慢的 Rank。
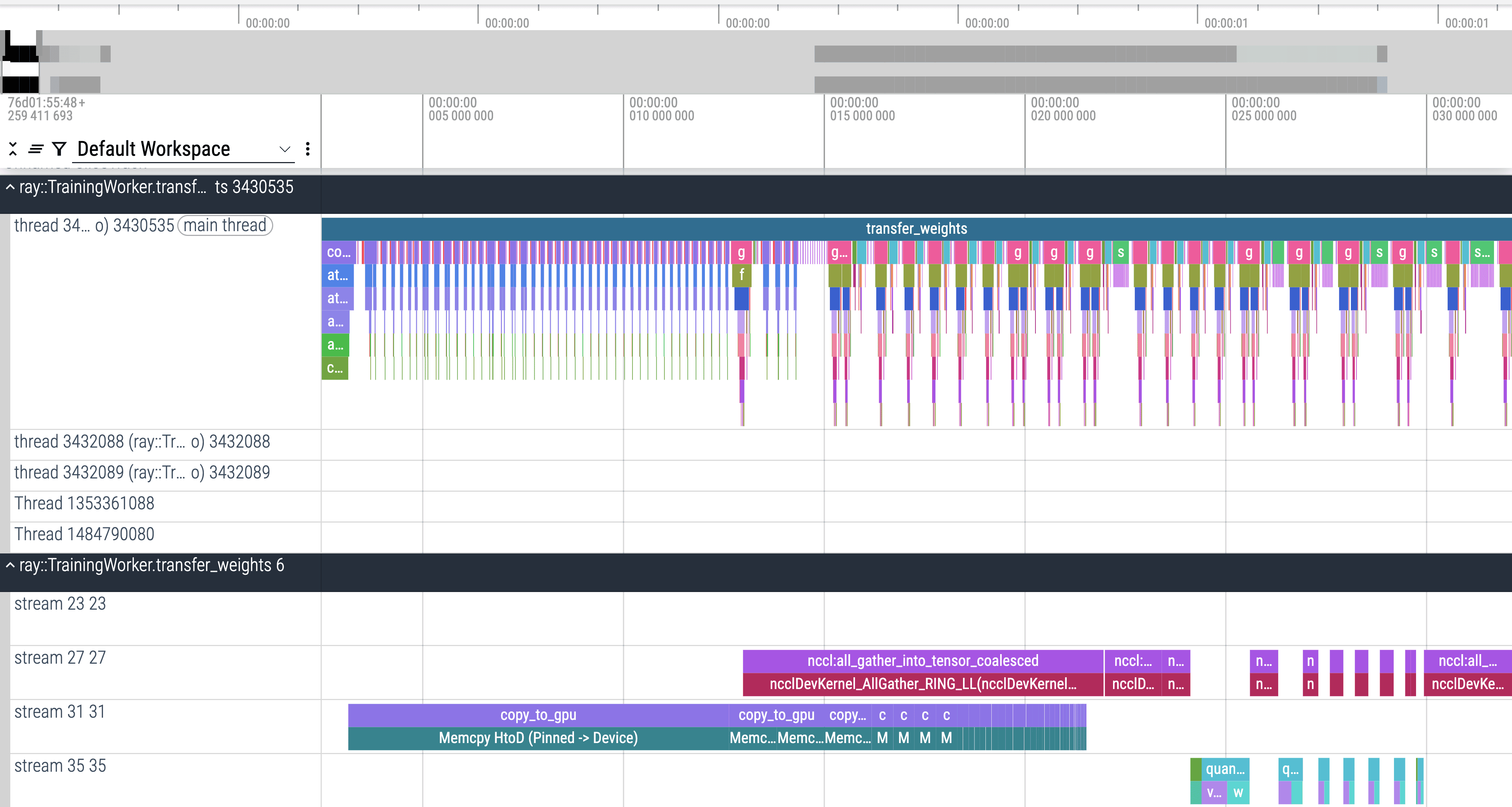
上面是放大看非 MoE 参数的传输。
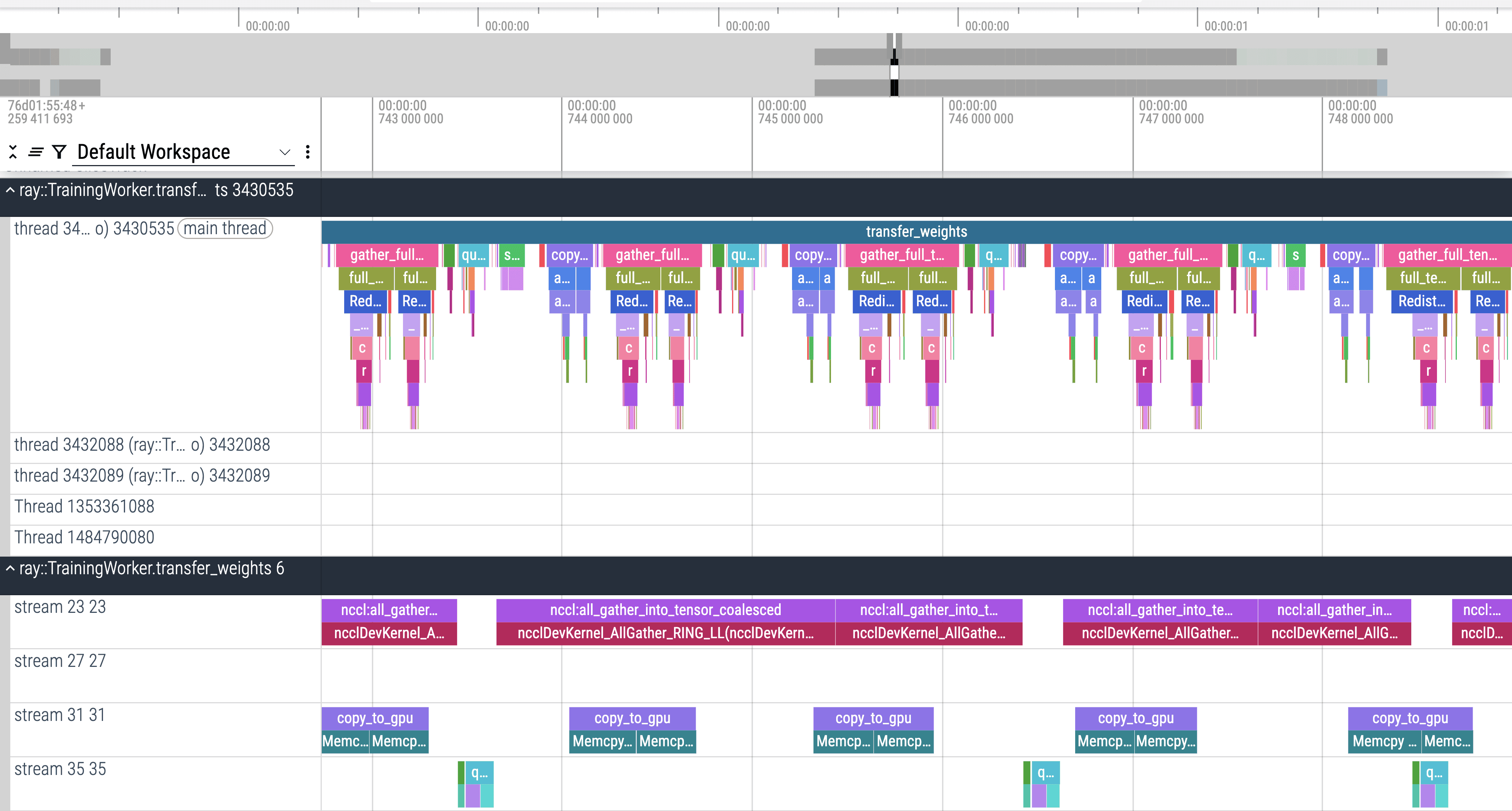
上面是放大看 MoE 参数的传输。
一个明显的区别是,对于非 MoE 参数,H2D Memcpy 是一口气完成的,而对于 MoE 参数,H2D Memcpy 始终是掺杂在整个时间线里面的。这说明 MoE 参数的传输任务并不是在一开始就全部开始的,而是随着前面一些传输任务的完成而逐步开始的。这说明 MoE 参数的传输可能撞到了我之前设置的最大临时内存限制。
补充一些图
Rank0-based 和 P2P 参数更新的对比

Torch.Distributed + RPC 和 RDMA 参数更新的对比
