跨机秒传RL模型参数更新的一些探索
我最近花了两周时间把 Qwen3-235B (BF16 训练,FP8 推理)的跨机(128卡训练,32卡推理)参数更新跑通了,只需要2秒。这篇博客我打算不单单是给读者呈现一个解决方案,而是记录一下我的探索过程,以及我的一些思考。过几天也会在公司博客上发一篇精简版。
起因
之前公司博客发的文章里面有提到,我们自己手搓了一个 LLM 推理引擎。另外大家也知道我司虽然不做预训练,但在后训练上花了非常多力气。所以说把我们自己的推理引擎接到我们的后训练框架上是一个很自然的事情。要做这个事情,第一步就是先搞定从训练节点到推理节点的参数更新。
因为我们用的是异步 RL 训练,所以训练和推理跑在不同的机器上。这样一来我在实现参数更新的时候就更简单了,连用 cuMem 把推理引擎的参数卸载掉都不用,直接把参数从训练节点传到推理节点就可以了。
当同事告诉我开源的 RL 框架需要好几分钟来更新参数的时候,我还是有点震惊的。比方说我们拿 DeepSeek 671B 来举例,就假设把参数切分到8张卡上好了,每张卡有 400 Gbps 也就是 50 GB/s 的网络,那把所有参数传出去也只需要 671 GB / (8 * 50 GB/s) = 1.68 秒。当然网络不可能跑到这么快,接收方也不止有一台机器,但反过来说模型也可能被切得更碎,并且训练节点也可能比推理节点更多。所以这些正负一抵消,我感觉参数更新的时间大概就是1秒这个数量级,再怎么样偏差也不可能到分钟级别。
不过现有方案跑得咋样跟我也没关系,反正我要做的是把我们自己的推理引擎接上去。我之前对训练这块也完全没了解过(读者读到后文就会惊呼,不是哥们,这你都不懂?),所以也懒得再去学习现有的方案是啥了,直接就开干。
预想的解决方案
读过我之前的教程或者读过公司博客的另两篇文章的读者应该有印象,我手搓了一个 RDMA 的通信库。所以在我的脑海里,传参数应该是一个和把大象放进冰箱里面一样简单的事情:
- 主控节点先把每张训练 GPU 和每张推理 GPU 上面的参数的元数据拿出来。
- 主控节点跑一个参数名的匹配
- 主控节点算一个固定的参数更新路由表,也就是每一个训练 GPU 需要把哪些参数发给哪个推理 GPU
- 主控节点把路由表发给每张训练 GPU
- 需要做参数更新的时候,主控节点只需要告诉所有训练 GPU 现在开始传参数啦。
- 每张训练 GPU 只需要按照路由表用 RDMA 把参数传给对应的推理 GPU 就好了。
- 推理 GPU 甚至都不知道自己的参数被更新了。
看起来这甚至都不需要修改我们的推理引擎,只需要在主控节点写一些很细致的参数匹配和路由表计算逻辑,以及在训练节点写一点调用 RDMA 通信库的代码就行了。
写成伪代码的话大概是这样子:
@ray.remote
class TrainingWorker:
def get_param_metadata(self) -> dict[str, ParamMeta]: ...
def set_routing_table(self, routing_table: RoutingTable) -> None: ...
def transfer_weights(self) -> None:
for entry in self.routing_table:
src_mr = get_mr(entry.src_ptr)
submit_rdma_write(src_mr, *entry)
wait_for_rdma_writes_to_complete()
@ray.remote
class RolloutWorker:
def get_param_metadata(self) -> dict[str, ParamMeta]: ...
def get_memory_regions(self) -> list[MemoryRegion]: ...
@dataclass
class WeightTransferEntry:
src_ptr: int
src_size: int
dst_ptr: int
dst_size: int
dst_mr: MemoryRegion
RoutingTable: TypeAlias = list[WeightTransferEntry]
def controller_main() -> None:
trainers: list[TrainingWorker] = ...
rollouts: list[RolloutWorker] = ...
trainer_params = ray.get([x.get_param_metadata.remote() for x in trainers])
rollout_params = ray.get([x.get_param_metadata.remote() for x in rollouts])
rollout_mrs = ray.get([x.get_memory_regions.remote() for x in rollouts])
schedule: list[RoutingTable] = compute_weight_transfer_schedule(trainer_params, rollout_params, rollout_mrs)
ray.get([trainer.set_routing_table.remote(routing_table)
for trainer, routing_table in zip(trainers, schedule)])
while training_not_done:
train()
ray.get([trainer.transfer_weights.remote() for trainer in trainers])
rollout()
RDMA 传输参数的概念验证
因为之前没了解过我们的训练框架,也没接触过 Ray,也没用过 slurm script,所以我打算一切从简,先验证一下我们的推理引擎能够接受 RDMA 传输的模型参数。
我的打算是用两个 GPU,一个跑我们的推理引擎,但是不加载模型参数,另一个按照我们推理引擎的格式加载模型参数,再把参数传给推理引擎。然后我们让推理引擎随便生成一点文字,如果参数传输是成功的,那么生成的文字应该是正常的。
对于这个概念验证,我也不需要用到我们训练框架的代码,所以我也不用着急去了解里面有什么。Ray 看起来也很好入门的样子,就一个 @ray.remote 一个 ray.get() 就能用了。然后 slurm script 也可以省了,反正我就用两块 GPU,在开发机上起一个 Ray 头节点就行了。
这样一来开发效率非常高,两天就搞定了。其中唯一遇到的困难是,有4个 tensor 总是会传输失败。
传输失败
首先我先尝试了一下遇到失败的时候重新传一次,但是无论怎么重试都不行,先睡几秒再传也没用。libfabric 给的错误信息也很模糊:
Unexpected status returned by responder
我在 libfabric 和 rdma-core 的代码搜了一下,不是特别能看出来是啥问题,这个错误是更底层的 EFA 驱动抛出来的。我隐约觉得可能是我的代码里面内存区域算错了,但是一般来说如果内存区域算错了,libfabric 的错误信息会说是 rkey 不对。
抱着路是问出来的心态,我先去问了问 AWS 的工程师。AWS EFA 团队的工程师也很给力,消息回的很快,他们也觉得这个错误消息很奇怪,他们也怀疑是内存区域算错了。
于是我就着重朝着这个方向去排查。首先我注意到的一个特点是,这4个传输失败的 tensor 都非常小,都不到 1KB(就是 FP8 Block Quant 的 inv_scale)。我怀疑就是我的 RDMA 通信库的分片算错了。
因为一张 EFA 网卡的速度不到 400 Gbps,所以 AWS 会给每张 GPU 多插几张 EFA 网卡(比如 p5 是4张100 Gbps,p5en 是2张200 Gbps)。所以我在 RDMA 通信库里面会把单个 RDMA WRITE 均匀地拆到所有 EFA 网卡上。然后我有一个小小的策略是,如果传输的数据太小(小于 MTU),那后面几张网卡就只传0个字节(0-length WRITE)。
然后我在算内存区域的偏移量的时候,没有特殊考虑 0-length,所以有可能出现最后一个 0-length WRITE 的指针正好在内存区域的末尾。众所周知,末尾都是开区间,所以其实这并不是一个合法的内存区域。
于是我在计算内存区域偏移量的时候,特判了一下 0-length WRITE,发现问题就解决了。
AWS EFA 的工程师告诉我,在 RDMA 规范里面,对于 0-length WRITE,是不需要验证目标方的内存区域的,但是 EFA 却还是做了检验。他们会把这个跟规范有偏差的地方改过来,也会改进错误信息。这里给 AWS EFA 团队点个赞!
获取 PyTorch 内存区域
熟悉 RDMA 或者读过我之前的 RDMA 教程的读者都知道,所谓内存区域就是4个东西:ptr, size, rkey, lkey。拿着 ptr 和 size 就可以在 RDMA 通信库里面注册内存区域了。但是我们要怎么拿到 PyTorch 分配的内存区域的元数据呢?
最朴素的办法当然是对于每一个 tensor,用 data_ptr() 得到指针,用 numel() * element_size() 得到大小。但这样需要注册非常多非常小的内存区域,感觉不是很优雅。我感觉既然 PyTorch 有内存池,那就把内存池里面的每个内存块都注册成内存区域不就好啦。
我本来以为得写一点 C++ 代码来把 PyTorch 内存池的信息导出来,好在在动手之前先搜索了一遍文档。我在 PyTorch 的文档里面找到了这么个函数:torch.cuda.memory.memory_snapshot()。这个函数可以返回 PyTorch CUDACachingAllocator 分配的所有内存块的指针和大小,然后我们就可以愉快地拿着这两个信息去注册 RDMA 内存区域了。
传输速度
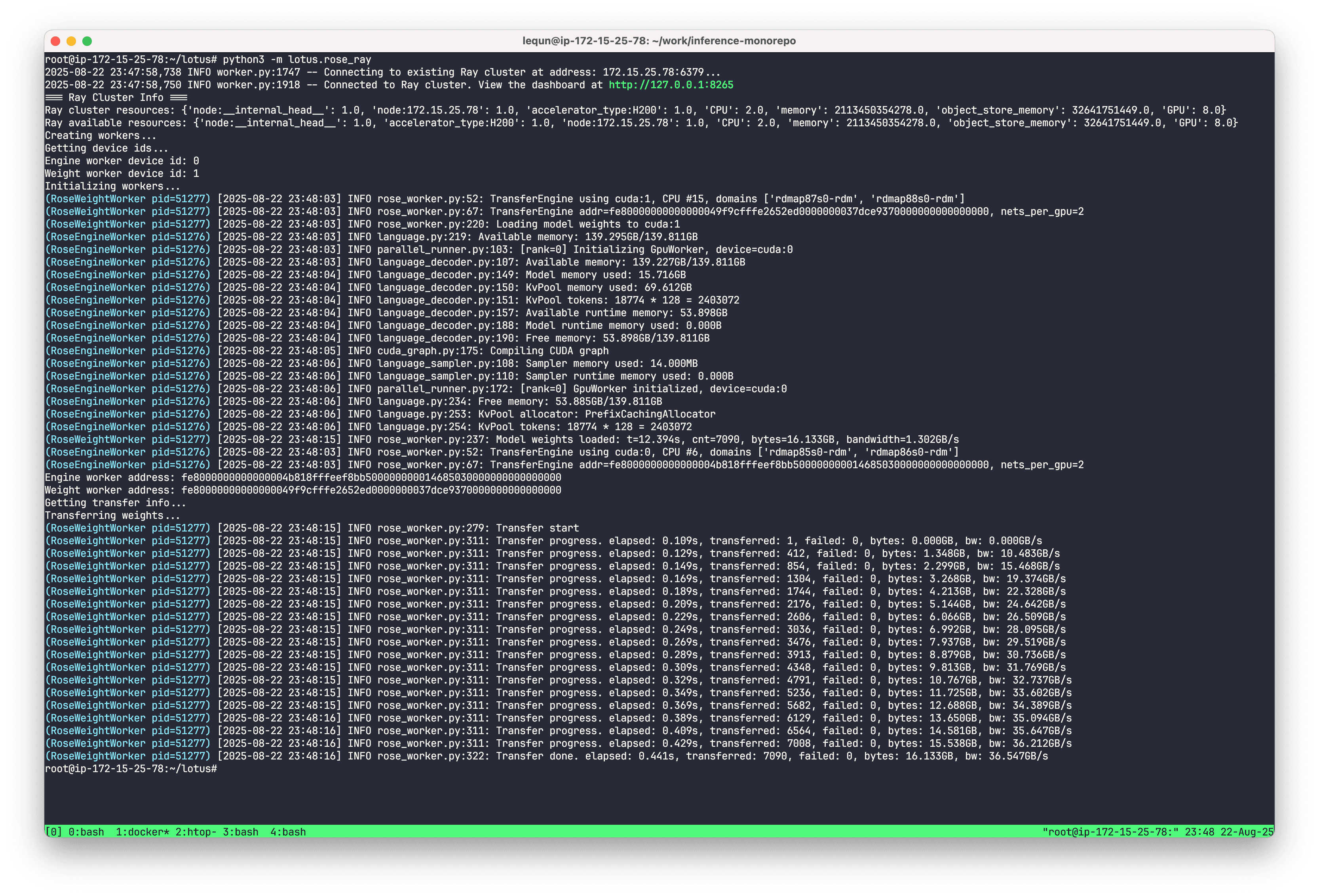
试了一下传输 DeepSeek-V2-Lite 的模型参数,大概 16 GB,花了0.44秒,大概 36 GB/s,这还是在没有预热的情况下跑出来的,我感觉很可以了。然后推理引擎在拿到参数后也能够输出正常的文字,说明参数传输是成功的。
真实的参数更新(惨败)
有了概念验证给的信心,我接下来就开始实现真实的参数更新了。我想着说先来个简单点的吧,就先考虑 DeepSeek-V2-Lite,也不考虑量化了,就先训练和推理都用 BF16。那在这样简化的情况下,唯一需要额外考虑的就是投影的融合了(比如把 {q,k,v}_proj 融合成一个 qkv_proj)。考虑到所有的融合都是在 dim0 上拼接的,而 PyTorch tensor 又是 row-major 的,所以其实在传输的时候也只需要加一个偏移量就好了。
于是我花了几天把参数名映射和路由表计算写了,训练节点只用1个 GPU 的时候也能跑通。我觉得这样拓展到8卡甚至多机训练也应该是没问题的,下一步就可以考虑量化了。然而现实却狠狠地打了脸。只要训练节点用了不止1个 GPU,我这套方案就跑不通,连 shape 都对不上。
仔细观察 shape 的差异,我发现差了8倍。我突然意识到,我一直以为 FSDP 就是普通的 DP,没想到它还把模型参数给做了切分。看了一眼 FSDP 的文档,一边在赞叹这个 API 做得好,一边又默默悲伤我的方案要推倒重来了。
真实的参数更新(推倒重来)
在看了 FSDP、DTensor 以及 DeviceMesh 的文档后,我意识到在计算路由表的时候,得按照 DTensor 的 Placement 来对参数进行切分。Placement 分成两种(不会出现 Partial),一种是 Replicate,另一种是沿着 tensor 的某一维 Shard。观察了一下我们训练框架产生的 Placement,最多切分一个维度。所以相对来说这个复杂性还比较低,要写的话很快可以写出来。总体的框架不用变,还是算好路由表直接 RDMA WRITE 就完事了。
DTensor
但是我马上想到了,如果我自己做这个切分的话,我还得自己算投影融合的各种偏移量,这个就更麻烦了。更加棘手的是量化,如果每个训练 GPU 的模型分片大小不能被 block quant 的大小整除,那还要二次计算那些处在边界上的元素。另外,FSDP 还可以把参数卸载到 CPU 上,这样我还得手动把数据从 CPU 传输到 GPU。
想了想,不如还是跟着 DTensor 的逻辑走吧。这样虽然做不到最快,但是起码很好写。只要做完 full_tensor(),DeviceMesh 里面的每一个 GPU 都拥有了完整的参数,可以很方便地计算投影融合以及进行量化。然后 DeviceMesh 里面的任意一个 GPU 都可以作为源,向有需要的推理节点传输参数。
DeviceMesh
注意到 full_tensor() 是一个集合通讯操作(对于 Shard Placement 而言,就是一个 all-gather),所以 DeviceMesh 里面的所有 GPU 都需要按照同样的顺序调用 full_tensor()。不同的 DeviceMesh 之间倒是不需要进行同样的集合通讯操作。
很自然地,我的下一个想法就是,看看到底有多少不同的 DeviceMesh,以及他们之间能不能并行呢?
好在这一题的答案也很简单。考虑 FSDP, PP, EP 这三个维度,假设一共有32卡, FSDP=2, PP=2, EP=8。首先无视掉 PP,因为它不对参数进行切分。对于非 MoE 参数(比如 {q,k,v}_proj),我们的训练框架会在 EP 维度上 Shard,在 FSDP 维度上 Replicate,所以一个 DeviceMesh 里面会有 2 * 8 = 16 卡,整个集群被分成两个不相交的 DeviceMesh,我们可以把它称为一个 DeviceMesh Group:
Non-MoE DeviceMesh Group:
DeviceMesh 0: 0~7 , 16~23
DeviceMesh 1: 8~15, 24~31
对于 MoE 参数,我们的框架在 FSDP 维度上 Shard,所以一个 DeviceMesh 里面会有2张卡,整个集群被分成16个不相交的 DeviceMesh:
MoE DeviceMesh Group:
DeviceMesh 0: 0, 16
DeviceMesh 1: 1, 17
...
DeviceMesh 15: 15, 31
因为一个 DeviceMesh Group 里面的 DeviceMesh 之间是没有交集的,所以他们可以并行地进行通信。我们只需要把整个参数传输的过程按照 DeviceMesh Group 进行划分就行了,在每个 DeviceMesh Group 传输结束后,需要放入一个全局的通讯屏障。
这个寻找 DeviceMesh Group 的过程很简单,随便写个贪心啥的就行了。
def find_disjoint_mesh_groups(mesh_set: set[Mesh]) -> list[set[Mesh]]:
"""Example:
Input: {
Mesh([range(0, 8), range(16, 24)]),
Mesh([range(8, 16), range(24, 32)]),
Mesh([0, 16]),
Mesh([1, 17]),
...
Mesh([15, 31]),
}
Output: [
{
Mesh([range(0, 8), range(16, 24)]),
Mesh([range(8, 16), range(24, 32)]),
},
{
Mesh([0, 16]),
Mesh([1, 17]),
...
Mesh([15, 31]),
},
]
"""
训推参数匹配
参数匹配是一个比较细节的活,当然我们可以根据肉眼观察规律来写一个匹配器,但是我还是想把这个匹配流程写的更加系统化一点。想象这是一个编译器,经过一个一个的 pass,我想要能够优雅地把路由表算出来。
首先为了区分有没有 quant scale,以及把 quant scale 和参数打包在一起,我先引入两个类:
@dataclass(slots=True, frozen=True)
class Identity:
base_name: str
@property
def weight_name(self) -> str:
return self.base_name + ".weight"
@dataclass(slots=True, frozen=True)
class Quantization:
base_name: str
scale_suffix: str
@property
def weight_name(self) -> str:
return self.base_name + ".weight"
@property
def scale_name(self) -> str:
return self.base_name + self.scale_suffix
然后我们可以写一个函数去把所有的参数名变成变成这两者之一:
def group_quant_weight_names(
scale_suffix: str,
weight_names: set[str],
) -> list[Identity | Quantization]:
"""
For example,
- ["foo.weight", "foo.weight_inv_scale"] -> [Quantization("foo", ".weight_inv_scale")]
- ["bar.weight"] -> [Identity("bar")]
"""
对于训练节点,我们需要考虑重命名以及投影融合。因为每个模型的规则是不一样的,所以每个模型需要写一个函数,输出一个从推理节点参数名到训练节点参数名的一个映射。在训练节点参数名这边,除了上面引入到两种类型,我们额外增加一种 ProjectionFusion,用来表示投影融合。
@dataclass(slots=True, frozen=True)
class ProjectionFusion:
weight_names: tuple[Identity, ...] | tuple[Quantization, ...]
class ModelWeightMatcher(Protocol):
def map_trainer_weight_name(
self,
trainer_quant_weight_names: list[Identity | Quantization],
) -> dict[str, Identity | Quantization | ProjectionFusion]:
"""
For example:
Input: [
Quantization("layers.0.attn.q_proj", ".weight_inv_scale"),
Quantization("layers.0.attn.k_proj", ".weight_inv_scale"),
Quantization("layers.0.attn.v_proj", ".weight_inv_scale"),
Identity("layers.0.mlp.down_proj"),
]
Output: {
"layers.0.attn.qkv_proj": ProjectionFusion(
weight_names=(
Quantization("layers.0.attn.q_proj", ".weight_inv_scale"),
Quantization("layers.0.attn.k_proj", ".weight_inv_scale"),
Quantization("layers.0.attn.v_proj", ".weight_inv_scale"),
)
),
"layers.0.mlp.down_proj": Identity("layers.0.mlp.down_proj"),
}
"""
有了这些铺垫之后,参数匹配就只剩下一些细致的检查了:
@dataclass(slots=True, frozen=True)
class WeightNameMapping:
trainer: Identity | Quantization | ProjectionFusion
rollout: Identity | Quantization
do_quant: bool
def match_weight_names(
trainer_named_parameters: dict[str, ParamMeta],
rollout_named_parameters: dict[str, ParamMeta],
matcher: ModelWeightMatcher,
) -> list[WeightNameMapping]:
trainer_quant_weight_names = group_quant_weight_names(trainer_named_parameters)
rollout_naming_map = {x.weight_name: x for x in group_quant_weight_names(rollout_named_parameters)}
trainer_weight_name_map = matcher.map_trainer_weight_name(trainer_quant_weight_names)
for expected_rollout_weight_name, trainer_naming in trainer_weight_name_map.items():
rollout_naming = rollout_naming_map[expected_rollout_weight_name]
# Expand shape by mesh placement
# Check shape, dtype, duplicate, etc...
生成路由表
生成路由表的逻辑也很简单,我们要生成的就是给每一个训练 GPU 算好要按照什么顺序把哪些参数传给哪些推理 GPU。
@dataclass(slots=True)
class WeightTransferEntry:
name_mapping: WeightNameMapping
rollout_workers: tuple[int, ...]
@dataclass(slots=True)
class WeightTransferGroup:
mesh_group: set[Mesh]
transfer_entries: list[WeightTransferEntry]
@dataclass(slots=True)
class WeightTransferRoutingTable:
groups: list[WeightTransferGroup]
@dataclass(slots=True)
class WeightTransferSchedule:
trainers: list[WeightTransferRoutingTable]
def generate_table_for_mesh_group(
trainers: list[ParametersMetadata],
rollouts: list[ParametersMetadata],
name_mappings_with_mesh: list[tuple[WeightNameMapping, Mesh]],
mesh_group: set[Mesh],
) -> list[WeightTransferGroup]:
transfer_entries_list: list[list[WeightTransferEntry]] = [[] for _ in trainers]
send_bytes = [0] * len(trainers)
for name_mapping, mesh in name_mappings_with_mesh:
owners = mesh.members()
for i_rollout, rollout in enumerate(rollouts):
winner = ... # min owner by send_bytes
# Assign winner to i_rollout
for owner in owners:
transfer_entries_list[owner].append(...)
def compute_weight_transfer_schedule(
trainers: list[ParametersMetadata],
rollouts: list[ParametersMetadata],
trainer_named_parameters: dict[str, ParameterMetadata],
name_mappings: list[WeightNameMapping],
) -> WeightTransferSchedule:
mesh_set: set[Mesh] = ...
mesh_groups = find_disjoint_mesh_groups(mesh_set)
trainer_tables = [WeightTransferRoutingTable([]) for _ in trainers]
for mesh_group in mesh_groups:
trainer_groups = generate_table_for_mesh_group(trainers, rollouts, name_mappings_with_mesh, mesh_group)
for table, group in zip(trainer_tables, trainer_groups):
table.groups.append(group)
return WeightTransferSchedule(trainer_tables)
唯一要注意的就是,前面提到了 full_tensor() 是一个集合通讯操作,所以这意味着一下两件事:
- DeviceMesh 里面的所有 GPU 都要按照同样的顺序执行
full_tensor()。哪怕某张训练 GPU 不需要把当前的参数传给任何推理 GPU,它也一样得调用full_tensor()。 - DeviceMesh Group 之间需要插入一个全局同步屏障
torch.distributed.barrier()。所以我们在生成路由表的时候,要把每个 DeviceMesh Group 的路由表区分开来。
在执行 full_tensor() 之后,DeviceMesh 里面所有 GPU 都拥有了完整的参数,都可以作为源,那么我们要怎么进行负载均衡呢?
因为 GPU 两两之间的 RDMA 带宽都是相同的,所以我这里用了一个非常简单的办法:统计每个训练 GPU 需要传输的字节数。对于每个参数,每个推理 GPU 都选择当前累计传输字节数最小的训练 GPU 作为源。
这个当然不是最优的解法,但是我感觉这个简单粗暴的方法应该已经够用了。
执行参数更新
实现完生成路由表,下一步就是实现在训练 GPU 上运行的传输逻辑了。这里有 GPU 操作(把参数从 CPU 读到 GPU、full_tensor()、投影融合、量化),还有 RDMA 网络传输操作。我想要把这两者并行起来。另外,为了防止爆显存,我还想能够在传输的过程中(大致地)限制最大的显存使用量。
我的做法大概是这样的。先给每一个传输任务搞一个类来存状态:
@dataclass(slots=True)
class _WeightTransferTask:
spec: WeightTransferEntry
num_transfers: int
total_bytes: int
# Step 1: Gather full_tensor() (async GPU operations)
weight_full_tensors: list[torch.Tensor] | None = None
scale_full_tensors: list[torch.Tensor] | None = None
# Step 2: Transform tensors (async GPU operations)
# Step 2a: Fuse projection
# Step 2b: Quantize on-the-fly
weight_tensor: torch.Tensor | None = None
scale_tensor: torch.Tensor | None = None
# Step 3: Wait for async GPU operations to finish
gpu_op_done: torch.cuda.Event | None = None
# Step 4: Submit RDMA transfers
submitted_transfer: bool = False
# Step 5: Wait for transfers to finish
finished_transfers: int = 0
def is_done(self) -> bool:
return self.submitted_transfer and self.finished_transfers == self.num_transfers
然后我们把所有的任务分成三类:
- 还没开始跑的
- 在等 GPU 操作跑完的
- 在等 RDMA 传输跑完的
class transfer_weights:
def __init__(
self,
fabric: TransferEngine,
model: nn.Module,
transfer_entries: list[WeightTransferEntry],
max_tmp_bytes: int = 1<<30,
) -> None:
self.tmp_bytes = 0
self.rdma_done_queue: Queue[_WeightTransferTask] = Queue()
tasks: deque[_WeightTransferTask] = deque()
for entry in transfer_entries:
tasks.append(_WeightTransferTask(...))
self.tasks_not_started = tasks
self.tasks_waiting_gpu_op: deque[_WeightTransferTask] = deque()
self.tasks_waiting_transfer: deque[_WeightTransferTask] = deque()
while self.tasks_not_started or self.tasks_waiting_gpu_op or self.tasks_waiting_transfer:
self._poll_progress()
然后我们每一次执行的时候,就根据任务的状态,决定跑什么,以及是否转变到下一个状态:
class transfer_weights:
...
def _poll_progress(self) -> None:
# Clear finished tasks
while self.tasks_waiting_transfer:
task = self.tasks_waiting_transfer[0]
if not task.is_done():
break
task = self.tasks_waiting_transfer.popleft()
self.tmp_bytes -= task.total_bytes
# Kick off async GPU operations
while self.tasks_not_started:
task = self.tasks_not_started[0]
if self.tmp_bytes + task.total_bytes > self.max_tmp_bytes:
break
task = self.tasks_not_started.popleft()
self.tasks_waiting_gpu_op.append(task)
self.tmp_bytes += task.total_bytes
self._to_device(task) # roughly: .to(device, non_blocking=True)
self._gather_full_tensors(task) # roughly: .full_tensor()
self._fuse_projection(task) # roughly: torch.cat()
self._quantize(task)
task.gpu_op_done = torch.cuda.Event()
task.gpu_op_done.record()
# Wait for async GPU operations to finish and submit transfers
while self.tasks_waiting_gpu_op:
task = self.tasks_waiting_gpu_op[0]
assert task.gpu_op_done is not None
if not task.gpu_op_done.query():
break
task = self.tasks_waiting_gpu_op.popleft()
self.tasks_waiting_transfer.append(task)
self.fabric.submit_write(
...,
callback=(lambda task: lambda: self.rdma_done_queue.put(task))(task),
)
task.submitted_transfer = True
# Handle completed transfer
while True:
try:
task = self.queue.get_nowait()
except Empty:
break
task.finished_transfers += 1
细心的读者可能注意到了,在执行 GPU 操作的时候,我们看起来调用的是阻塞式的函数,但是其实这里并不会真的阻塞。我在这里走的一个弯路是我试图在 .full_tensor() 的时候使用 async_op=True 改成异步的,然后用 AsyncCollectiveTensor.completed 来检测是否完成。然而这样做始终会传出错误的参数,除非我加一个 time.sleep(0.01)。在仔细看了 Torch Distributed 关于异步的语义的文档之后,我才明白,这里 completed 只是说提交到了 Cuda Stream,并不是代表这个操作完成了。
而 PyTorch 的 kernel 调用其实也都只是把操作提交到 Cuda Stream,所以除非我们显式地要求同步,不然这些 GPU 操作也不会阻塞我们的 Python CPU 线程。所以我之前在这里用 async_op=True 完全是画蛇添足。
那么怎么知道 GPU 操作完成了呢?一般来说我们写 PyTorch 代码的时候不需要关心这个,因为所有的操作都是提交到 default stream 上面的。但是在这里,我们需要一个非阻塞的方法来知道 GPU 操作完成了,然后才能让 RDMA 传输开始。要实现这个,我们可以在提交完所有的 GPU 操作之后,插入一个 Cuda Event,然后通过 event.query() 来知道 GPU 操作是否完成了。
另外,以上代码是用来传单个 DeviceMesh Group 的,别忘了要加入一个全局通讯屏障。
@ray.remote
class TrainingWorker:
def set_routing_table(self, routing_table: WeightTransferRoutingTable) -> None: ...
def transfer_weights(self) -> None:
for group in self._routing_table.groups:
transfer_weights(..., group.transfer_entries)
torch.distributed.barrier()
至此,我们的实现就完成了。
秒传 Qwen3-235B FP8
经过一些简单的调试,这一次的代码很轻松地就跑通了 DeepSeek-V2-Lite(BF16 训练,BF16 推理),然后我又试了一下加上 FP8 block quant,也顺利地秒传了。对于 Qwen3-235B(BF16 训练,FP8 推理),我稍微改了一下投影融合的规则,然后也非常轻松地跑起来了(128卡训练,32卡推理)。
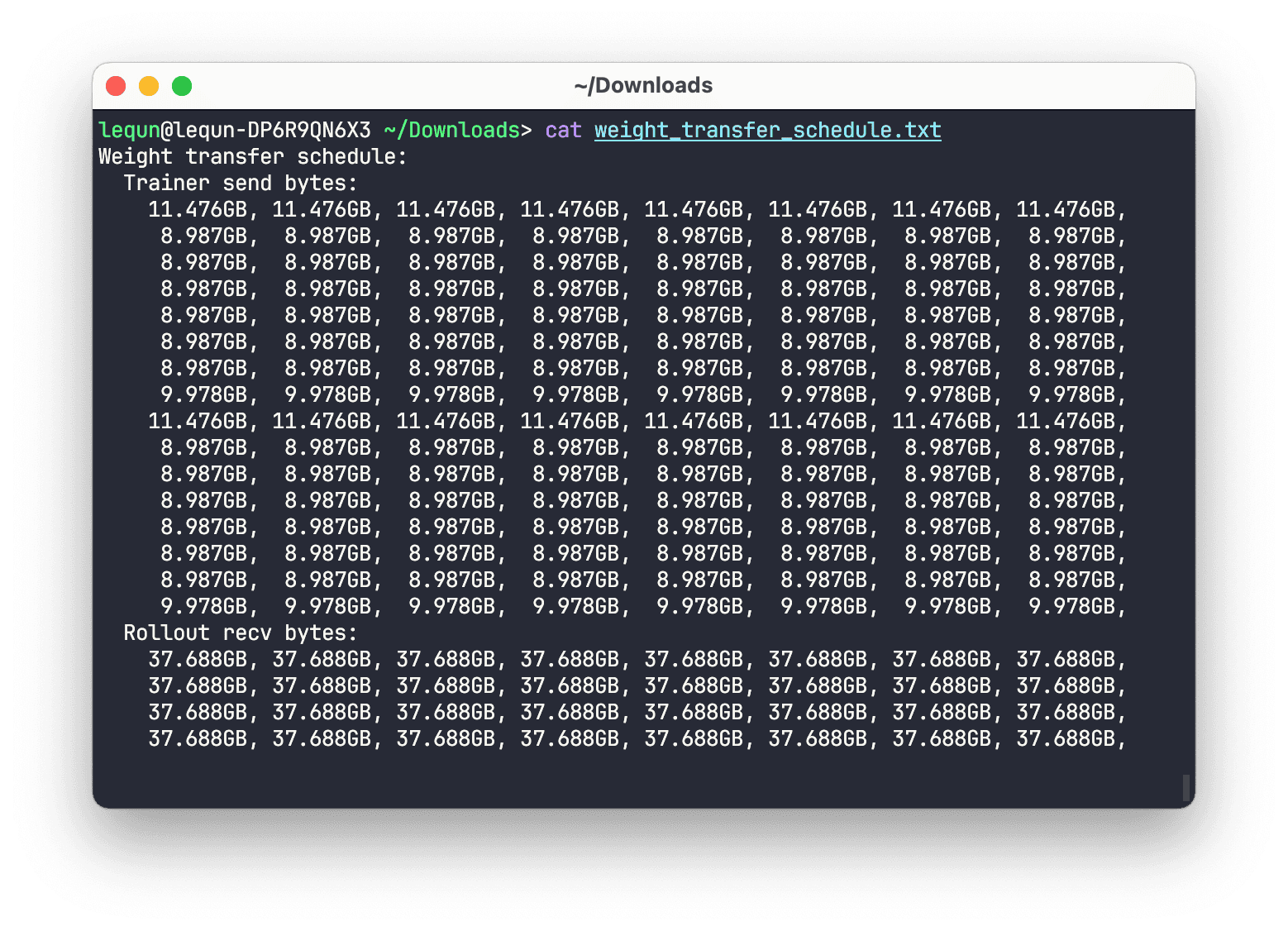
上图可以看到根据路由表算出来每张训练 GPU 需要发送的字节数,以及每张推理 GPU 需要接收的字节数。虽然有些不平衡,但也马马虎虎。
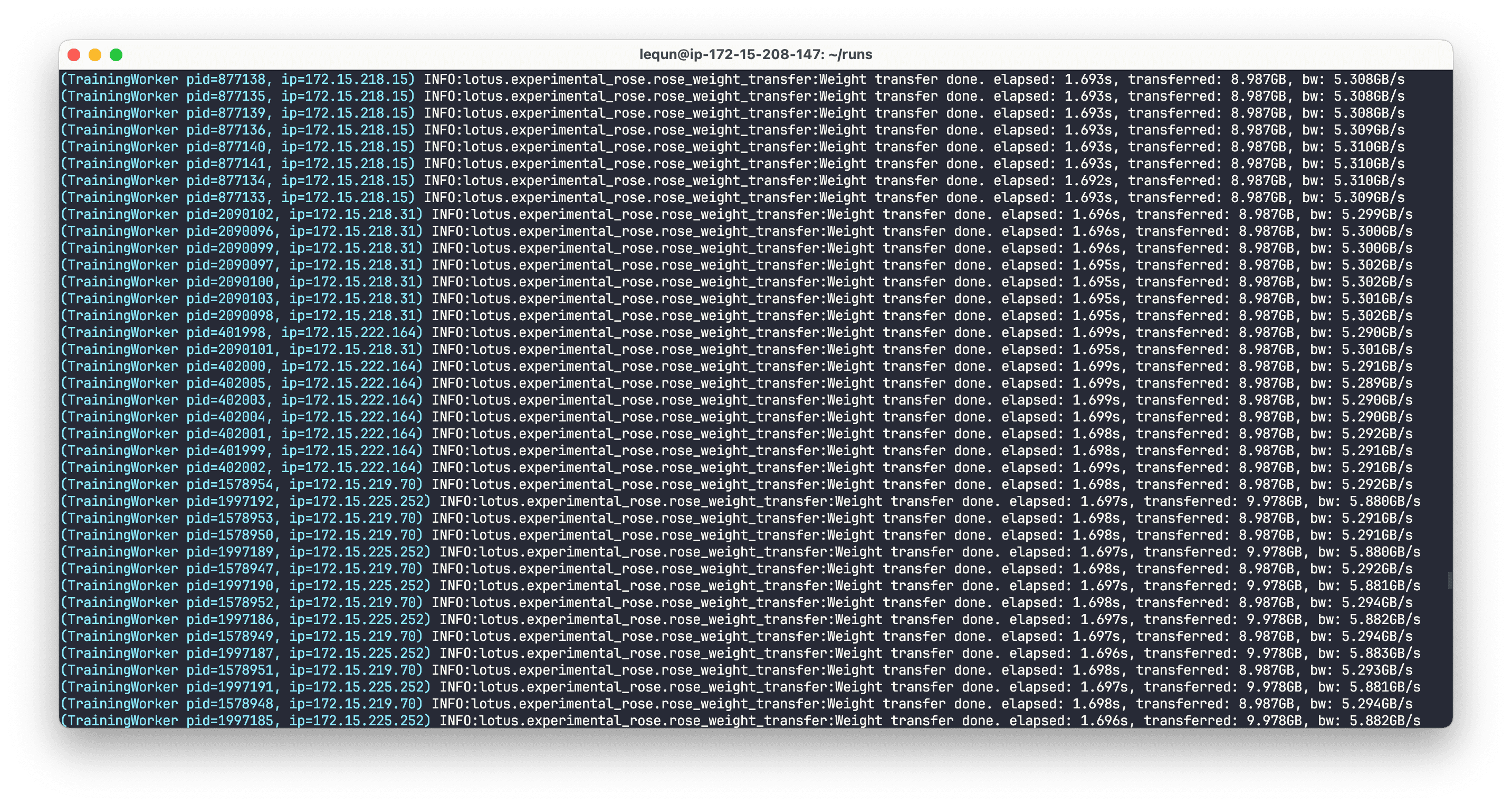
上图可以看到,一次完整的传输啪地一下就完成了,只花了不到2秒。虽然传输的带宽只有大概 5 GB/s,跟 50 GB/s 的上限以及之前概念验证跑出来的 36 GB/s 有很大的差距,但是考虑到这里我们做了很多的 GPU 操作,或许也是可以理解的。
为什么跑不满带宽
虽然我没有打算着急做更多的优化,不过我还是想知道为什么离跑满带宽还有那么大的差距,我想知道这些时间都花在哪里了。所以我就多插了一些 Cuda Event,算了算时间。
目测了一眼数据,发现主要还是慢在提交 GPU 操作以及等待 GPU 操作完成上面。过两天我再仔细汇总一下数据,然后回来补个分析。
为什么现有框架跑不快
(这里没有拉踩同行的意思,我只是想从门外汉的角度猜测一下为什么现有框架跑不快,如果说得不对欢迎指正。另外,我们自己的推理引擎和后训练框架支持的功能都非常有限,只关注几个我们特定的场景,而不是各种复杂功能的排列组合,所以工程实现以及优化都不需要考虑太多兼容性问题,比较容易落地。用我们这种精简功能的框架去跟成熟的框架比,也对成熟的框架不公平。更不用说在开源社区能够协调这么多贡献者和用户也是很不容易的事情。我这里只有对同行深深的敬意。)
对现有框架的快速调研
因为我对 RL Infra 这个领域不熟悉,所以不太清楚现有的框架更新参数具体需要多少时间。看到一个比较新的数据是来自两周前的博客:
目前 slime 可以做到 7s 完成训推一体下 Qwen3 30B-A3B 模型 bf16 权重的参数同步。100s 完成 GLM4.5 355B-A32B 的 fp8 blockwise 量化 + 参数更新。
(UPDATE: 2025-09-08 @朱小霖 提供了一个更新的数据)
在训推分离的配置下(64 卡训练,64 卡推理),slime 中 Qwen3 235B-A22B 从训练这边的 bf16 参数更新至推理测的 fp8 参数大约需要 8s
NeMo-RL 上个月也有一篇博客介绍他们对权重更新的优化。
另外Chayenne的这篇博客也对权重更新的几种主流的方案做了一个很好的总结:
update_weights_from_disk:写磁盘读磁盘,简单透明,性能取决于存储系统的快慢。update_weights_from_distributed:把参数聚合到训练节点的 rank 0,然后发到推理节点的 rank 0,然后再从推理节点的 rank 0 发到推理节点的其他 rank。update_weights_from_tensor:类似update_weights_from_distributed,对训推一体有特殊优化(比如传递 Cuda IPC Handle),但是对推理引擎需要有侵入式修改。
一些猜测
没跑过现有的框架,没做过性能测试,没仔细读过代码,所以这里我就开始胡说八道了:
- 只依赖 rank 0 进行训练节点和推理节点之间的通信,那么 rank 0 GPU 就是整个通信的瓶颈。GPU 和网卡通过 PCIe 连接,所以再快也不可能快过 PCIe 的带宽。因此整机的通信速度就被卡死在了单卡的 400 Gbps (50 GB/s),而不是 3200 Gbps (400 GB/s)。
- RPC 额外开销太大。如果每传一个 tensor 都需要 RPC 调用一次推理引擎的方法,那么这些控制平面的消息传递本身就会花很多时间。我猜 RPC 是跑在 TCP 上的。另外,序列化反序列化也是需要时间的。
- 没有充分利用并行和流水线。每个 tensor 的更新是可以按照硬件资源的不同划分成不同阶段的。不同的硬件资源可以并行地进行不同的阶段。比如 GPU 操作和 RDMA 传输可以并行。但是因为担心爆显存,很多时候不得不一个 tensor 一个 tensor 地传(或者一层一层地传),这就导致不能充分利用并行和流水线。
- 重复计算及重复传递传输方案。
- 工程实现上将太多步骤耦合在了一起(例如参数匹配、传输方案计算、投影融合、量化、机内传输、跨机传输、显存用量控制),在一堆乱麻中可能很难理清思绪。
而我上面提到的方案就像把冰箱门打开,把大象装进去,然后关上冰箱门,因为:
- 训练节点的每张卡都可以向外传参数,推理节点的每张卡都可以接收参数。因此所有的 RDMA 带宽都能用上。
- 推理框架不需要修改,不需要任何控制平面的 RPC 消息。推理节点甚至都不知道自己的参数被改了。
- 每个 tensor 的传输任务划分成了3个阶段:提交 GPU 操作,等待 GPU 操作完成并提交 RDMA 传输,等待 RDMA 传输完成。每个任务只要完成了上一阶段,马上可以进入下一个阶段。只要硬件腾出资源,就可以开启下一个 tensor 的传输。
- 启动训练的时候计算一次传输方案并下发,之后每次需要更新权重的时候只需要执行传输方案就行了。
- 传输方案的计算以及传输方案的执行各自都分成了几个阶段,方便实现,也方便写单元测试。
那既然用 RDMA 点对点传输这么简单方便,为什么现有框架不这么做呢?我猜测是因为没有好用的 API。
大家手头上能用的 API 就是 torch.distributed,而 torch.distributed 底下跑的是 NCCL。虽然 NCCL 和 torch.distributed 也支持点对点通信,但是非常不灵活:
- 发送方
send(tensor)和接收方recv(tensor)需要给定同样类型、同样大小的 tensor。 - 传输是阻塞的,也就是发送方
send(t2)需要等待send(t1)完成,接收方同理。
然而 RDMA 的点对点传输非常灵活且高效:
- 接收方无需任何操作。接收方甚至都不知道自己的内存被改了。
- 传输的大小及目的地内存地址都是可以灵活指定的。
- 传输是异步的,不会阻碍发送方或接收方。
- 所有的数据传输都不会经过 Linux 内核。用户态程序直接向网卡提交 RDMA 操作。网卡可以直接从内存或者显存中读取数据。
你需要的或许是一个 RDMA 通信库?
经过一段时间的探索,我们发现有了 RDMA 通信库之后可以很方便地做很多事情,比如 KvCache 传输,训练参数更新,甚至一些你想不到的事情也能做。然后我们的通信库在 AWS EFA 上也越来越稳定,性能也越来越好。最近我正在加 ConnectX-7 网卡的支持。我们很快会开源这个通信库,敬请期待。
另外,对我司感兴趣的读者,也欢迎给我们投简历。
更新
2025-09-17 更新:跨机秒传RL模型参数更新的一些后续